.jpeg)
Implementing “Exactly once” data delivery in distributed / streaming systems is no easy endeavor.

In this blog post, we’ll walk through a couple of strategies we implemented in Epsio for end-to-end “exactly-once” data delivery that are a-bit different from “traditional” approaches. Specifically, we’ll explore how the ability to access or pull data from downstream systems can alleviate some of the challenges that existing systems and algorithms face.
The issue of exactly once delivery
At first glance, exactly once delivery in stream processing may appear trivial. You consume a stream of changes, apply a transformations, and write the results to a destination. What could possibly go wrong?
As we all know though — the world isn’t lollipops and sunshine, and sometimes, our infrastructure can fail. When this happens, other than our alerting system lighting up like a Christmas tree — our stream processors must handle the failures that happened gracefully, ensuring that downstream data remains correct and consistent.
This means that even under failure scenarios, the stream processor must guarantee that every inputted change is applied to the sink exactly once: no more, no less.
Problematic Scenario #1 — Connection to Sink Breaking
The first (and easier to handle) failure scenario is when the connection to the sink breaks during a batch write or delete operation.
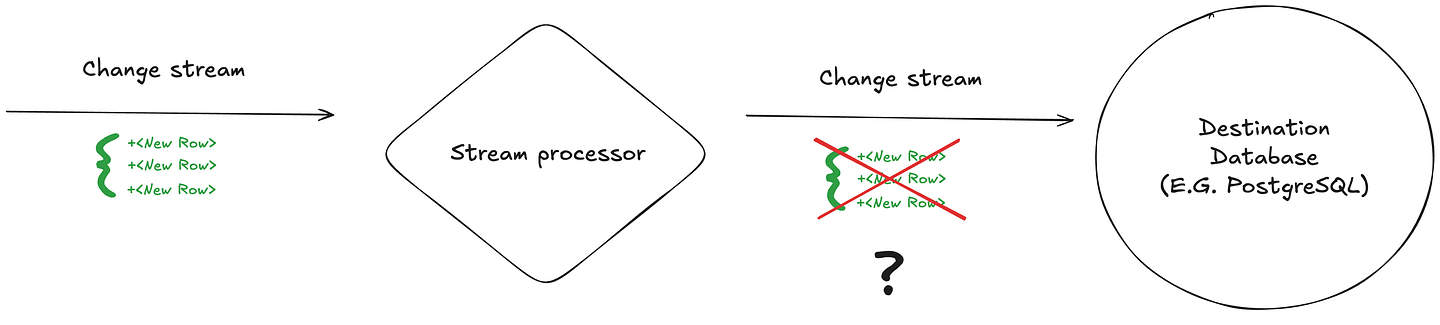
This can happen either because of a network hiccup, a sink/database restart, or because someone in your team decided to “just try something real quick” on prod and messes up all the network routes.
When this failure occurs (e.g., an insert operation receives a timeout or a TCP connection breaks forcefully mid insert), the stream processor is left in the dark: did the sink manage to apply any of the writes before the disconnect? If we retry the operation blindly, we risk duplicating data. But if we skip it, we could lose records altogether.
To handle this, Epsio employs one of two strategies, depending on the capabilities of the target sink:
Utilizing transactions
Luckily, many of the data sinks we work with have transactions built-in. This makes life much easier because we can apply a batch of changes in bulk, and if our connection breaks in the middle — all is good because the transaction wasn’t committed yet! For example:
BEGIN;
INSERT <change1>
INSERT <change2>
INSERT <change3>
COMMIT;
If for some reason, the server disconnects between insert2 and insert3 — we know the previous inserts didn’t get committed yet — so we can just restart the entire write operation when we re-establish the connection and commit. Great, right? No need to worry about duplicate writes anymore?
…
…
…
…
…
…
WRONG!
In the world of data processing, we need to be prepared for failure at ANY POINT IN TIME. This include the specific time when we run the COMMIT command. If the connection breaks while we perform the COMMIT — how can we know if the transaction was committed (and not that the reply confirming the COMMIT just never reached us?), or if we need to re-apply the transaction?
You might think this scenario is fairly rare (how often does a database restart? And how unlucky must one be to have a restart exactly on the commit command) — but this is something that actually happened many times for some of our users (when running many views and writing into many data stores that frequently upgrade/restart due to scaling events).
Surprisingly, some of the most famous stream processors (Flink included!) market themselves as “exactly once” stream processors, but can’t handle this edge case:
“If a commit fails (for example, due to an intermittent network issue), the entire Flink application fails, restarts according to the user’s restart strategy, and there is another commit attempt. This process is critical because if the commit does not eventually succeed, data loss occurs.” — An Overview of End-to-End Exactly-Once Processing in Apache FlinkAn Overview of End-to-End Exactly-Once Processing in Apache Flink
Epsio, on the other hand, overcomes this by utilizing a built-in feature many data stores have to check if a specific transaction ID was committed. This means that when the engine needs to decide whether to re-apply the changes to the sink, it can just check if the previous transaction ID was committed or not. For example, in PostgreSQL:
BEGIN;
SELECT xid_current(); -- Save this for later. If commit fails, check txid if was committed
INSERT <change1>
INSERT <change2>
INSERT <change3>
COMMIT;
If the COMMIT command fails, Epsio simply checks if the transaction ID was previously committed or not and decides if it needs to re-apply all the changes again.
Making writes idempotent
Sometimes, transactions aren’t available in the data sink — so Epsio has to “cheat” its way into achieving exactly-once change delivery.
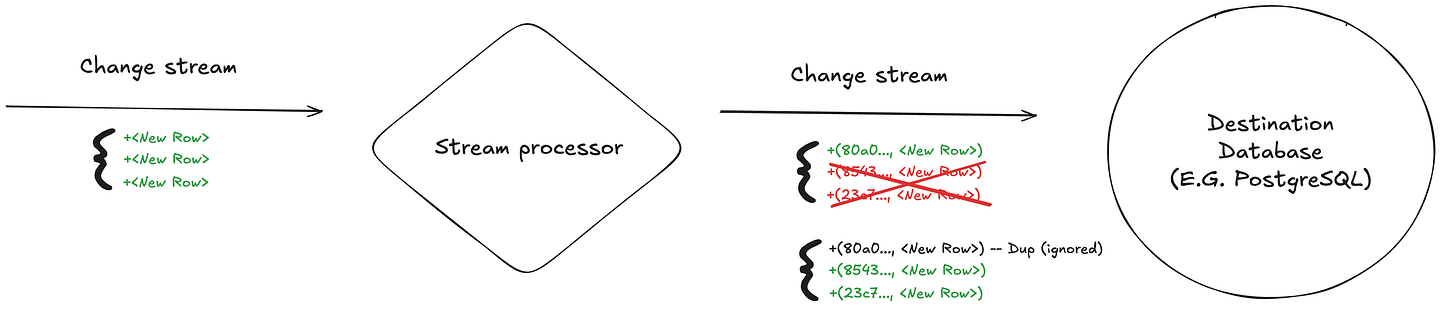
Instead of trying to guarantee that a change is written only once to the datastore, an alternative approach is to make the write process idempotent: if a particular change has already been written, any subsequent attempt to write it again will be safely ignored.
Epsio handles this by assigning a unique identifier (UUIDv7) to each change before it’s sent to the sink. It then relies on unique indexes (or similar constraints) in the target datastore to ensure that duplicate writes are ignored — typically by using an UPSERT or merge operation.
For example, if a batch of three changes is being written to the sink and the connection drops after the first change is written, retrying the batch will result in only the remaining two changes being applied. The first change, already present, will be ignored.
Problematic Scenario #2 — Engine crashes Mid-Processing
A more complex (and interesting!) scenario arises when the stream processor itself crashes or restarts mid-processing.
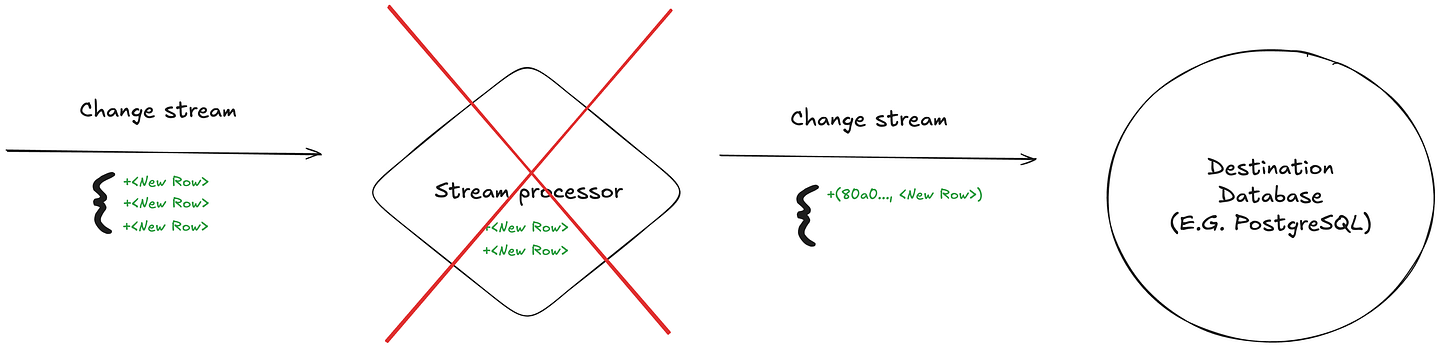
In this scenario, it’s unclear how the processor should proceed upon recovery. How does it know which changes were already written? How does it continue to ensure no duplicate changes are written to sink, even in the scenario of state data loss?
Traditional stream processing systems — ahem, ahem, Flink — handle this by combining end-to-end transactions with periodic state checkpoints. Here’s how it works:
- For each input batch, start a transaction in the sink.
- Process, transform and write the batch into the sink (using the transaction opened in previous stage)
- After fully processing the batch, back up the internal state (key-value store, input stream offsets, metadata, etc.).
- Commit the transaction after all steps are successful.
If a failure occurs mid-processing, a “replica node” (a node sitting in standby) can revert to the last successful checkpoint/backup. Since the transaction isn’t committed while the batch is still being processed, any partially outputted changes from this batch are discarded, and the replica node simply retries processing the entire batch.
The huge (!) downside of this approach — is that the “frequency” of your transactions is highly limited by how fast you can perform checkpoints and backup all your internal state. Consider Confluent’s default checkpoint interval of 1 minute — this overhead means that achieving exactly-once guarantees in Confluent’s Flink implementation currently requires accepting at least 1 minute of latency in your stream processing pipeline.
“Exactly-Once: If you require exactly-once, the latency is roughly one minute and is dominated by the interval at which Kafka transactions are committed” — Delivery Guarantees and Latency in Confluent Cloud for Apache FlinkDelivery Guarantees and Latency in Confluent Cloud for Apache Flink
How does Epsio solve this?
Unlike traditional stream processors that function as a “one-way street,” continuously receiving data from sources and pushing it downstream, Epsio is bidirectional. This means it can not only push data to the sink but also pull data from it when needed.
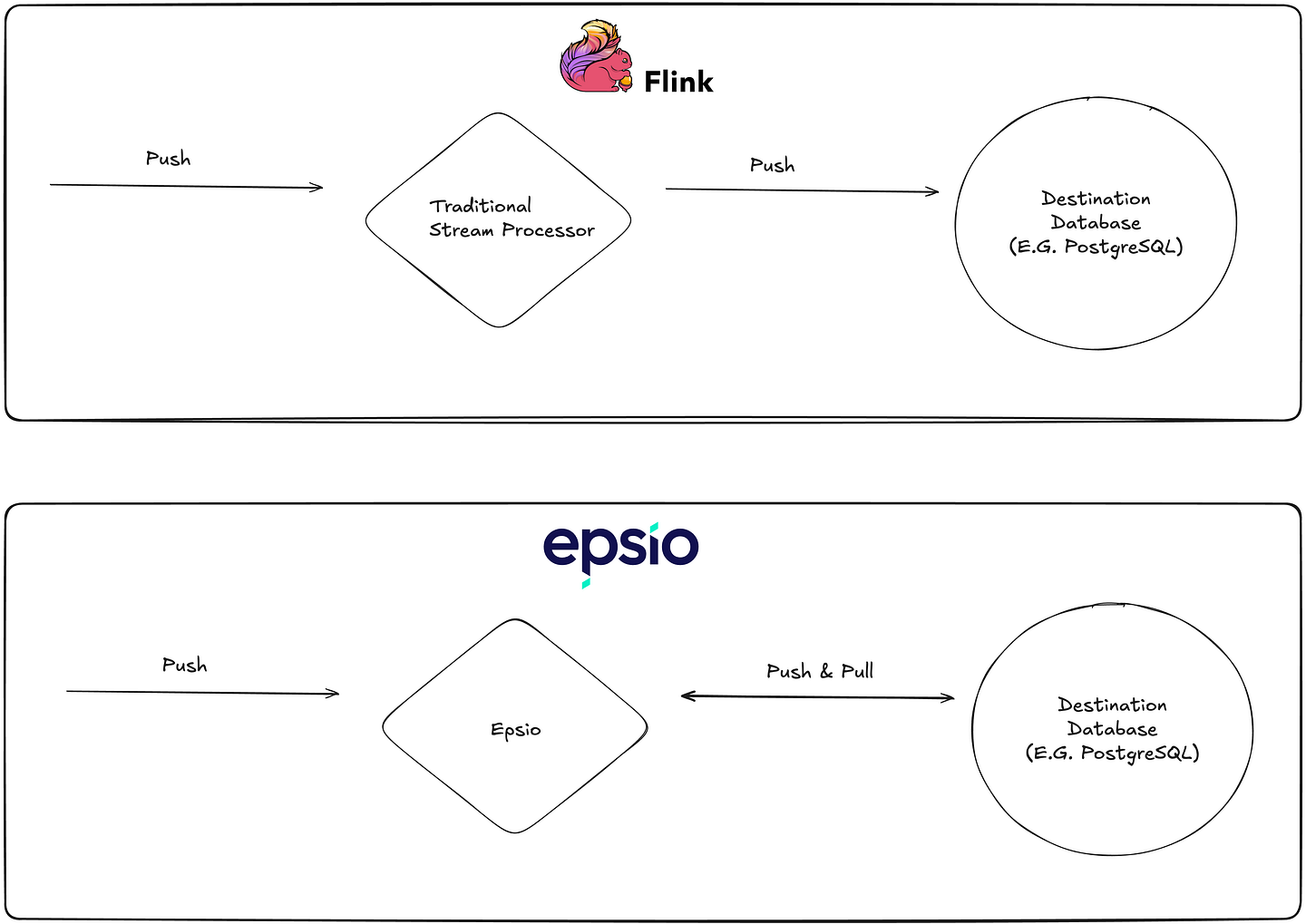
This bidirectional approach is crucial because it enables failure recovery in ways that traditional stream processors can’t. While traditional processors simply push data to the sink, Epsio can pull data back from the sink during failure scenarios and compare the current state in the sink with its expected internal state — thereby avoiding outputting changes it already outputted.
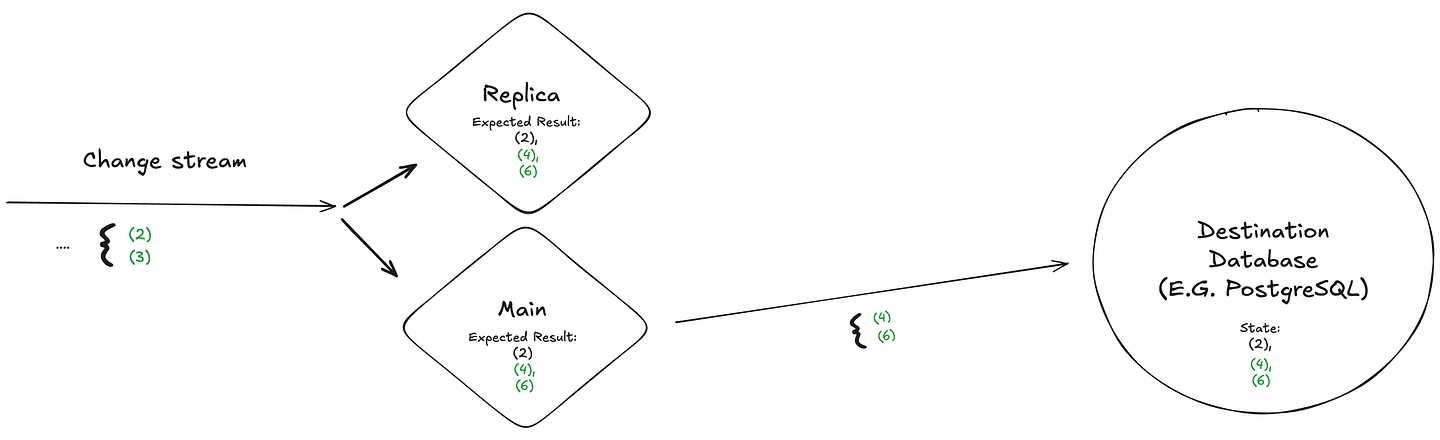
For example, consider a highly available Epsio deployment with a “Main” instance and a “Replica”. This system receives a stream of changes and multiplies each input integer by 2. To prepare for failure scenarios, the replica will continuously maintains internally the “expected” result state of the sink.
When a failure occurs, the replica will pull the current state from the sink, compare it with its expected state, and apply only the differences (ie new rows that need to be inserted / deleted).
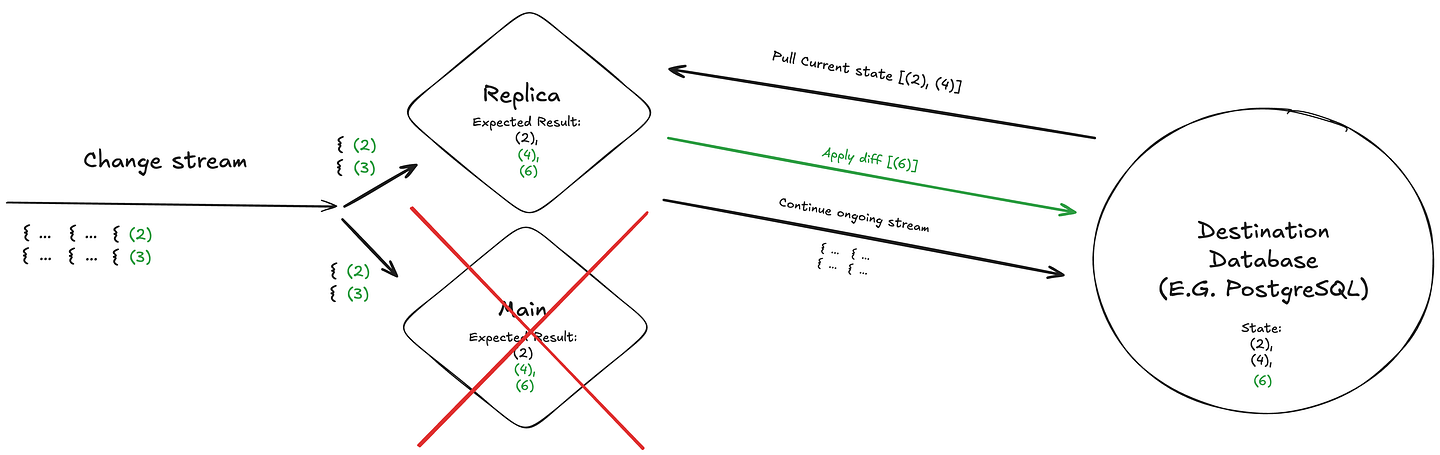
After applying these changes, the replica can just continue ingesting more events from the input stream, and never worry about duplicate data delivery being an issue.
Because this approach doesn’t require any external checkpoint/backup, and more importantly decouples sink writes from state backup frequency, it enables users to achieve strong “exactly-once” delivery guarantees without sacrificing streaming latency.
What about distributed streaming transformations, or streaming transformations that don’t sink into a datastore?
At this point, many readers might be thinking, “But our stream processing is distributed across many instances & stages, not only a single stage that writes into a sink”
While these scenarios differ from the single-instance case, our approach of a “stream processor that interacts better with it’s neighbors” can theoretically be also highly beneficial for distributed transformations as well!
Instead of only pulling data from the final data store (like a database), each processing node can pull information from the node that comes after it in the pipeline. Think of it as each node being able to ask its downstream neighbor: “Hey, what changes have you recently received?”
Imagine for example a chain of streaming transformations operating on an input stream. The first node duplicates each received change, while the next node converts each ingested change into a string and appends a smiley face (because dammit, integers deserve to be happy!):
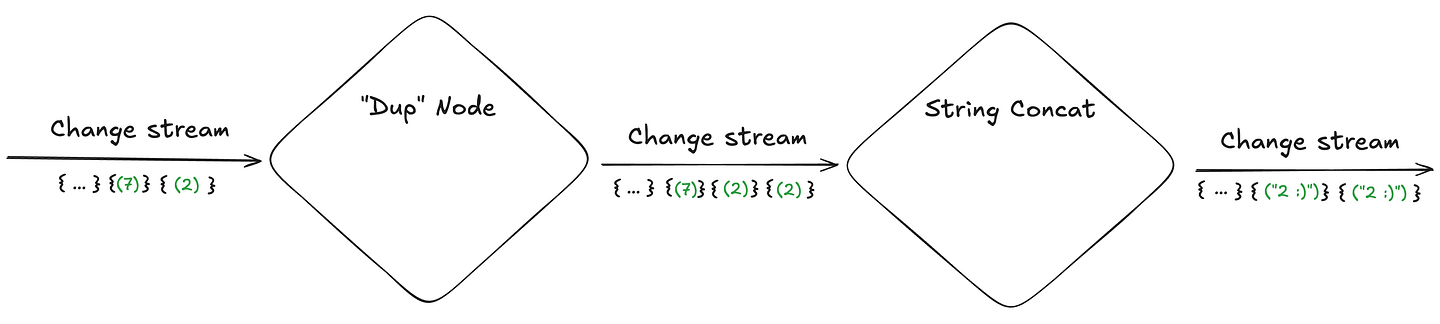
To enable reliable recovery, a streaming engine can implement the following strategy:
- Tag each received change with its location in the input stream and preserve this “tag” with all derived changes (when a change is duplicated/edited, all copies receive the same “location in input stream” tag). This mechanism allows a node, in the event of a crash, to request only the most recently processed changes — rather than retrieving the entire change history.
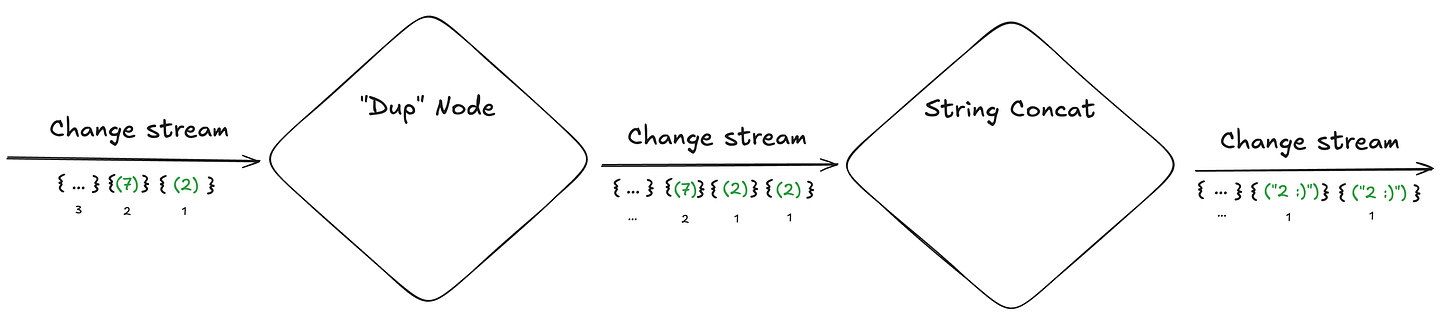
- Add internal state within each operator. Specifically:
- The current “location” in the source change stream it is currently processing.
- All changes it has already received from the previous node in that location.
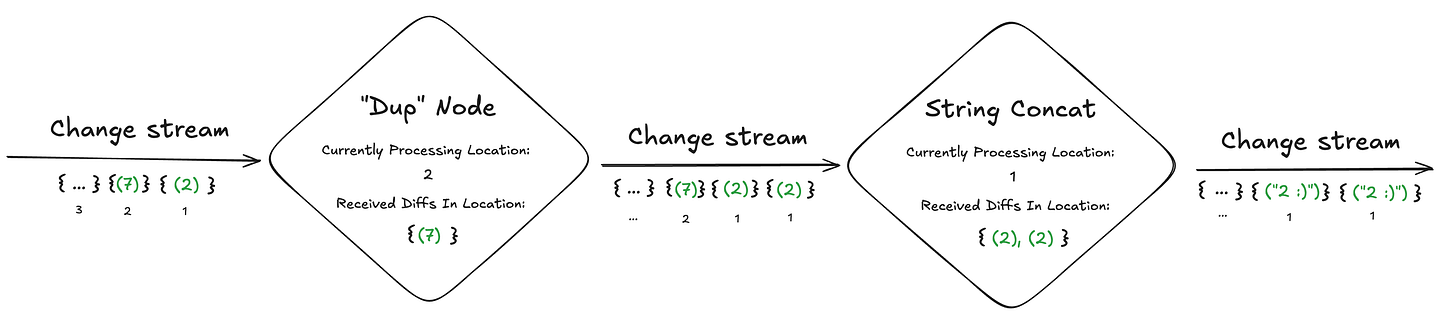
3. Within each “replica” node, maintain:
- The current location the next operator is currently processing (achieved by either periodically polling the downstream node or by receiving “advancement” notifications)
- All changes it “expects” to output for that specific location (continuously updated based on the input stream)
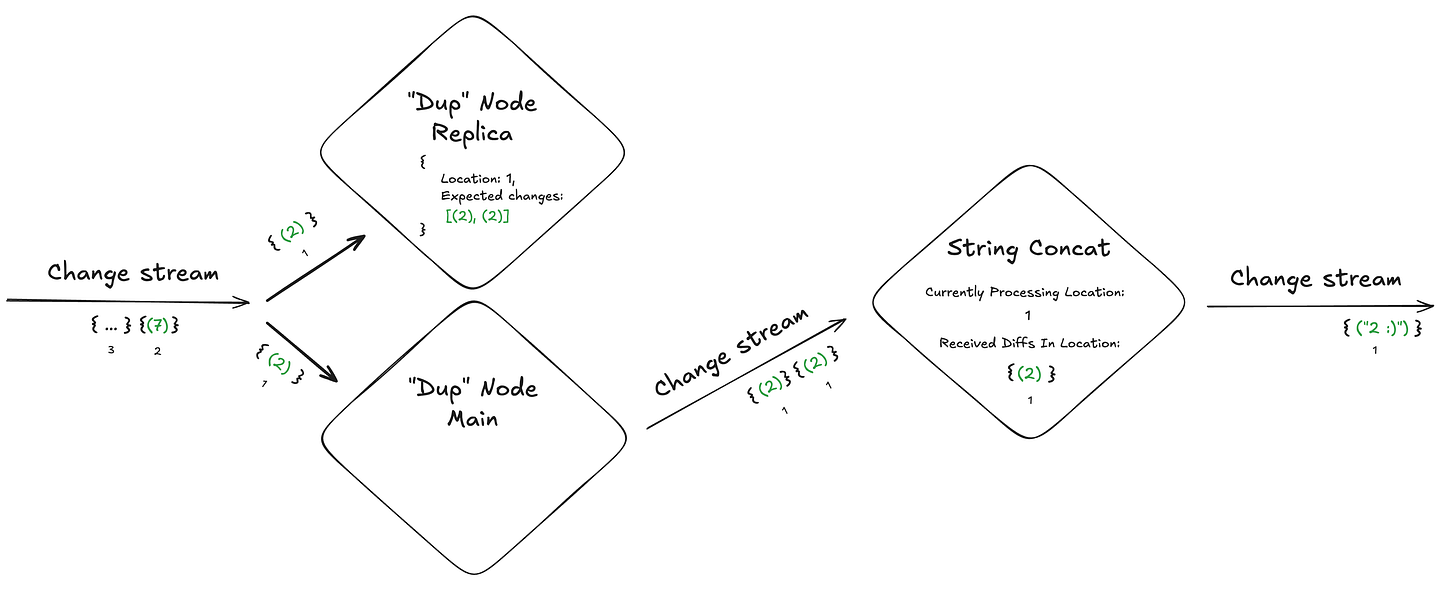
When a node fails, its replica can “pull” from the downstream node the current location + diffs it already processed and determine which additional changes need to be outputted for that specific location.
For example, if our duplication node received “(2)” as input and crashed after sending only one “(2)” to the next node (when it should send two copies), the “Dup” node replica can pull the changes the concat node already received, recognize that another (2) is missing for the current location, and send the additional (2) to complete the operation.
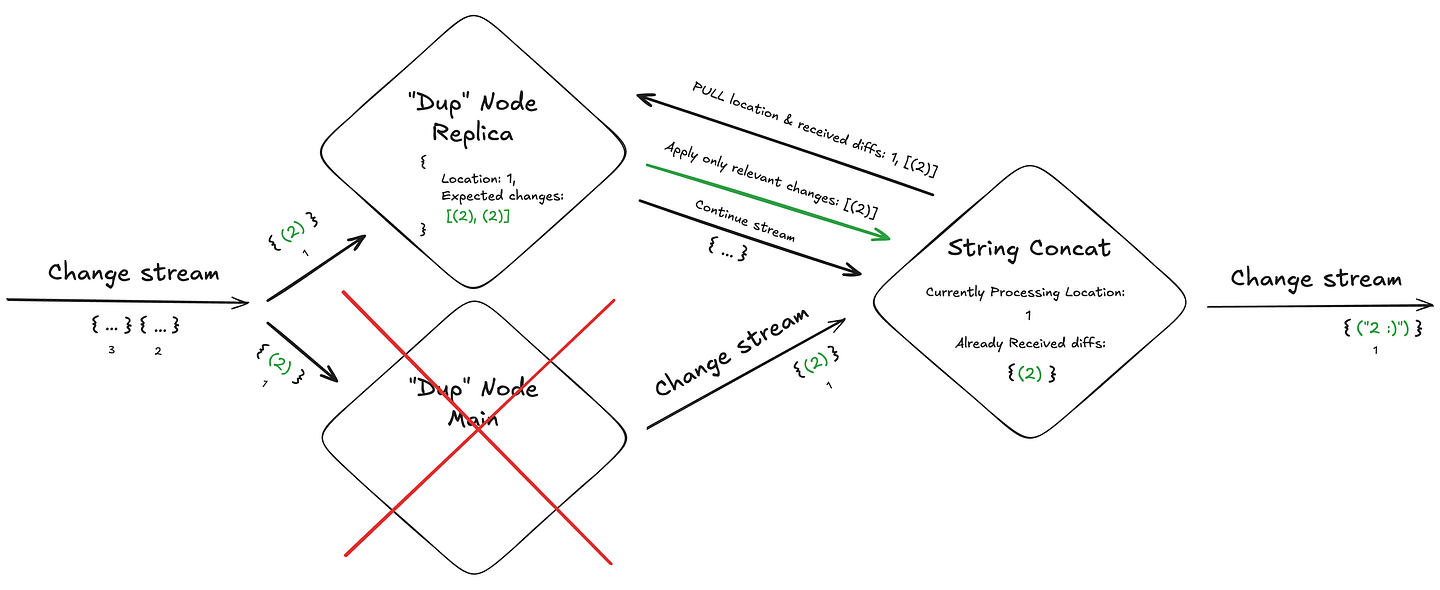
This way, the stream processor is able to gracefully recover from a crash event without breaking the exactly once delivery guarantee, and more importantly — without hurting the end-to-end latency!
Concluding Thoughts
Historically, stream processors have been built to operate in isolation — generic, self-contained components with minimal awareness of their upstream and downstream counterparts. While this approach has merit, it comes with significant trade-offs.
While there are still many things to talk about in the above “strategy” (how can you deal with the scenario multiple instance crash, how do you deal with a scenario where the sink dataset is too large to efficiently maintain on the instance, etc…) — I hope this article gave you a small glimpse into how stream processors could become significantly easier to use — and more efficient — if they were designed to be more “aware” of the surrounding ecosystem.